3. Learning & Memory
In its most reduced model, learning is simply the transmission of information from sensory input into long-term memory, with a few checkpoints along the way. In a wider sense, there are infinite ways in which we can learn things and seemingly infinite categories of learning we can partake in. Furthermore, learning is not just about committing a fact to long-term memory—learning a skill is as different from memorizing a fact as it is from developing a habit, yet all can be viewed as some form of learning or memorization.
Some things, like our native language, are codified early on in life, without us really having a choice or making a conscious effort. Others, like playing a musical instrument or riding a bike, require enough deliberate practice for us to eventually treat the act as one of muscle memory. As we discussed in Chapter 1, the ability to delegate complex tasks to our subconscious plays a large role in cognitive economy. Once a task requires little to no conscious attention, it becomes less taxing to perform, allowing us to apply focus elsewhere—should we need or wish to—while we perform it.
This process—known as automaticity—is integral to developing skills and habits. Repeatable actions with predictable outcomes soon become ingrained, and the neural networks responsible for performing these skills and tasks, or for reciting information, become more easily activated and accessible. While we don’t necessarily lose the ability to perform certain skills after not doing them for a while—we literally have an idiom of just like riding a bike to explain the phenomenon of our ability to perform certain tasks or skills after long periods without doing so—these skills can be subject to fading, which is just as it sounds: a reduced capability, or a need for much more focus and attention than before, to perform certain skills or tasks.
Yet the role of cognitive economy in learning does little to explain the complex emotional and motivational structures behind the vast majority of our decisions or desires to learn something new. This is where goals come in to play. Aside from facts we pick up and remember seemingly at random, the overwhelming majority of the knowledge, skills, and habits we learn and develop over time are preceded by a goal. Sometimes that goal involves simply understanding more about the world we live in—studying biology, for example, to satisfy an innate curiosity of how the body and its systems function. Other times, that goal is more tangible or emotional in nature. We may fall in love with a piece of music that inspires us to learn an instrument, which unto itself might reveal many different goals—reaching a level of proficiency to play that particular song, or creating your own music in the vein of that piece. Almost every musician I know, including myself, can trace their musical career back to that one song that led to decades of deliberate practice sparked by a single emotional response.
Our goals are also almost always unique to and intrinsic to us. We may learn Japanese due to a desire to travel to Japan and engage more deeply in the culture there. We may learn to use a drill so that we can put up a shelf in order to display our favorite books. And we may even try to learn how to do a sick backflip to impress our attractive neighbor. (The last one is definitely just a hypothetical example, I promise.) While we’ll explore some of the neuroscience of learning, and indeed most of what we discuss will be through delving into the inseparable relationship of cognition and emotion when applied to learning, I want to make clear that the goal behind the need or desire to learn is just as—often more—important than the processes of learning themselves.
Goals
A quick aside, while we’re on the subject of goals: never conflate the internal, organizational goals of your company or product with the motivations of people. If someone uses a product to send money to others, their goal is not necessarily to “perform a bank transfer,” and it’s absolutely not to “tap the transfer button, input the transaction details, and then tap send.” We’re often far too guilty of conflating interactions with goals, but there’s always something deeper, something further removed—physically and metaphorically—from the screen that should inform our thinking. Frameworks like Jobs To Be Done go some way to helping us avoid this, but conflating success metrics and KPIs with actual human motivation and goals is something that far too many inexperienced designers and product people do.
Why does someone need to transfer money? Perhaps to split a bar tab with their friend? How would your app change were you to design around that potentiality? Perhaps they send money to pay off a debt, or to pay a seller on an auction site, or maybe it’s a charitable donation—all unique goals that one would expect to be framed and executed uniquely, with the utmost care and specificity. Whatever the product, without understanding the real-world goals that inform its features, we limit ourselves to designing around the shallowest potentialities.
More often than we’d like to admit, a person’s goals when using our work are far, far removed from actions that actually take place within our interfaces. We need to become more comfortable with accepting and embracing transience in our work. There’s always an external driver to the actions that occur in our interfaces, and often the best thing we can do is to design so effectively for seamlessness that our interface becomes invisible. There is absolutely no shame in creating a wonderful environment for the “just- passing-through” crowd. A product or service that lets people pop in, do what they need to do, and enjoy the fruits of their labor is an all-too-rare find in this age of stickiness, mindshare, and habit-forming.
Indeed, the modern-day fetishization of attention far too often distorts our vision for our work. It suggests that the more engaging our products are, the better they can be perceived as performing. At best this is a gross abstraction, at worst, it’s just categorically wrong. Generally, people aren’t looking for engagement; they’re looking for solutions to their problems. They’re looking to be enabled and empowered in their pursuit of a goal. At the risk of generalizing, here’s a hypothesis: most people want to engage with their banking app about as much as they want to engage with their alarm clock.
Even for media-streaming products such as Netflix and YouTube, our goal is not to “engage with the app.” It’s escapism, or education, or just outright entertainment. The fact that roughly 94% of my interactions with Netflix involve scrolling through with my partner and taking it in turns to say “Nah, not tonight” to every suggestion we see doesn’t mean Netflix has created an engaging interface. It means that, firstly, finding a good show is hard work and, secondly, the interface is apparently doing a poor job of presenting us with viable solutions to that problem.
Mindful design principle: acknowledge real world goals
Your product’s KPIs and success metrics don’t matter one bit outside of your team or your company. People come to your product with their own goals and motivations, and if they achieve what they came to do, observe their success in the real world. People don’t want to ‘click X button’ or ‘perform Y action’, they want to finish a job, or show their love, or express their creativity. Your product is not an island.
So, this puts us in a bit of a conundrum. As you’re about to read, repetition is key to learning. Learning something well enough begets automaticity. Automaticity reduces the mental energy and focus required when performing that task. So, people should use our stuff all the time, right? Well—and you’re going to get sick of me saying this—it’s again all about balance.
How we Learn
While the most interesting and challenging aspect of designing around the human learning process lies, in my opinion, in the creation of a positive and enriching environment, it’d be remiss to not explore the basics of our learning processes first. The subject of human learning is extraordinarily broad with wide-reaching implications. Thus, the science of learning and memory is rife with debate, controversy, and ethical considerations. With that in mind, we’ll cover some of the basic principles of learning and then zone in on where we can really make an impact with our work while leaving the shouting and debating to the professionals.
As mentioned at the beginning of this chapter, learning can be (over-)diluted into the act of transferring sensory data into long-term memory storage. Broadly speaking, we hear or read a fact or observe a technique, and through some form of practice or repetition, we commit it to memory. This process involves said sensory data traversing a few checkpoints along the way, with data loss or corruption often occurring between each stage. Furthermore, for most humans, this process is rarely a straightforward A-B-C flow of information; it’s almost always a messy and chaotic back-and-forth between our different memory storage and retrieval structures.
Our brain is a living ecosystem of neurons and synaptic connectors—a universe wherein stars burn out and are born anew. If we were to observe the light show of the brain’s neural activity during learning, it’d be akin to watching a time lapse of our galaxy shifting over millennia. As we learn and meditate on new information, connections between neurons are reinforced, allowing them to better communicate. New connections between neurons are formed, existing connections are occasionally dimmed, and new neurons themselves may even be created. The more often a neural network associated with a specific task is strengthened and activated, the more efficient it becomes. This shifting structure at the brain’s cellular level is what is known as plasticity—the idea that our brains are living, malleable things, brimming with life and complexity, constantly changing until the day we die.
It’s this neural strengthening and cellular rearrangement that allows us, over time, to relegate the performance of certain tasks to the back of our mind. Essentially, when the neural network used for a certain task is strengthened enough through consistent engagement, it allows for a level of efficiency in neural communication that requires very little conscious thought. When this happens, our default mode network is able to engage, we pay less attention to the task, and we can perform it intuitively and seamlessly. When discussing this journey from stimuli to stored memory, you’ll often encounter three key concepts: encoding, storage, and retrieval.
Encoding
Encoding is a cognitive process that involves taking information from our environment and, essentially, formatting it in a way that makes it easier to store and retrieve later. We can see encoding as an extension of our attentional system—it’s selective, and there needs to be a degree of salience to a stimulus for us to focus on it to encode it in the first place. Once focused on a stimulus or piece of information, we will more often than not perform some form of re-coding to help with memorisation. Sometimes recoding is a conscious effort to help us remember something, such as creating a mnemonic, like how we might be taught to remember the planets as—and I’m going to show my age here—My Very Easy Method Just Speeds Up Naming (Planets), with the order representing each planet’s proximity to the sun. (Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, Neptune and… the now-famous Not A Planet, Pluto. RIP little fella.) Other times this re-coding is subconscious, and we’re attaching information to events and contexts without really being aware of it.
The re-coding process is also prone to error. When we allow certain information to be attached to certain events or existing memories, we can color both the new information and the older memories with new contexts and connections. This is where the phenomenon of unreliable memories comes from—everything from our existing biases and schemas through to unrelated stimuli from the environment in which we encoded can distort the information and memories that we store. Often, we’re better at misremembering what we inferred from an experience than we are at remembering the experience itself.
All memories must be encoded, but not everything we encode will be memorized. There’s no hard and fast rule that tells us what kind of encoding or recoding guarantees a successful or failed storage of memory. There are of course ways to give our brains the best chance.
Storage
While encoding information lets us perceive and recode signals into something our memory system can deal with, storage explains how we pass this information through the various layers of memory, eventually cataloging it in our long-term memory.
Storage starts at the sensory level. While most people will be familiar with the concepts of short-term—or working—memory and long-term memory, this sensory layer of our memory system is often overlooked. Our sensory memory lets us hold a stimulus in our memory for a very brief period of time, even if it is no longer present. For visual information—otherwise known as iconic memory—this is usually a fraction of a second, and provides a kind of sensory buffer, allowing us to perceive a coherent sequences of events—similar to how we can watch a movie recorded at 24 frames per second and perceive it as one continuous sequence rather than a disjointed series of extremely rapid individual frames. Alongside iconic memory, we have echoic memory, which is essentially the same concept but applied to sound. We have a much higher capacity for echoic memory, usually up to a few seconds, and this is integral to our ability to comprehend language, engage in conversations, and follow spoken directions.
Storage next occurs, at a more active level, in our short-term memory. Otherwise known as working memory, our short-term memory is where we store information during cognitive processing. Our working memory is limited in capacity, especially when compared to our long-term memory—assumed by many to be infinite—and presents some limitations that we have to be extremely mindful of when designing. When information is being held in our working memory, it can add a cognitive load. Asking people to keep too many things in mind, or make too many decisions at once, can result in their working memory capacity being exceeded, potentially resulting in cognitive overload, stress, and anxiety.
All the concepts we explored in Chapter 1 with regards to the cost of distractions apply just as much to the cost of storing information in our working memory. And just like how the threshold for attention switching and focus differs for any individual, so too does the capacity of any one person’s working memory. Similarly—and intrinsically linked—to our ability to hold focus, our capacity for working memory can also be influenced by external cognitive impairments, neurodevelopmental disorders, and mental health issues. Anxiety and stress, ADHD, depression, generational trauma, dyscalculia, poverty, and even the knowledge that we have an unread email in our inbox can all impact our capacity to hold information in our working memory.
You might have encountered Miller’s Law in your studies or career. It’s an often-cited concept, also known as ”magic number 7”, that suggests a rule of thumb of 4 to 7 items as a capacity for our working memory. This often gets translated into quirky design principles like “limit your navigation to a maximum of seven elements”—which is somewhat useless, unless viewed in its vaguest form of “don’t present too many options”. While we can store single items in working memory, it’s not a cut-and-dry capacity where one item takes up one slot. More often, when we talk about capacity, we’re actually talking about chunks of information. This is where we get back to our good friend grouping. (I told you it was going to come up a lot!) By splitting information up (think about how we can use Gestalt to visually group related elements) we can create a chunk of information. An elementary example of this is a phone number, let’s say 5554206969. While there are ten digits to this number, it doesn’t necessarily mean we need ten ‘slots’ of working memory to hold that number in our heads. In fact, phone numbers across the world are almost always hyphenated—pre chunked, for our convenience. Our totally fake phone number, were it printed in a phone book or displayed on a contact page, would quite likely be presented as 555-420-6969. Much nicer. This gives us three chunks of information to hold in our memory:
- Chunk one: 555
- Chunk two: 420
- Chunk three: 6969
Some people will argue that the length of each chunk also should adhere to Miller’s Law—that is, no chunk should exceed seven characters—but there really is no hard and fast rule when it comes to working memory chunking. As previously mentioned, there are myriad circumstantial, mental, and physiological reasons why someone’s working memory might be seemingly limited or expanded when compared with a stereotypical average—if such a thing exists. The type of information being processed, too, will have an impact. Some people have an incredible knack for remembering numbers. To them, perhaps even the non-chunked phone number is trivial to hold in their working memory. A person with dyscalculia, though, might struggle to keep even a three-digit chunk in their working memory. That doesn’t mean that they’d naturally be bad at remembering a sequence of playing cards, or a list of countries and capital cities.
Rather than having a reductive ”only show four to seven items” approach to design, what we really want to do is limit the need to hold chunks of data in working memory. There are a few ways we can achieve this, and we’ll touch on them very soon, but let’s get that out of our working memory, for now!
The next stage of storing information is our long-term memory. This is where we consolidate information from our working memory into a more solid, retrievable state. What actually happens during this consolidation is quite incredible: our brains manipulate our nervous system—reinforcing and creating neural connections in the same vein we’d leave a Post-It on our monitor to remind us of an important note. These memory traces—also known as engrams—can sound like the stuff of science fiction: if the brain manipulates the nervous system to leave notes for itself, could we reverse engineer them to replay memories? That’s dystopian as heck, though, and we’ll save that one for the neurobiologists. What we need to be aware of is that, although memory traces sound sophisticated, they’re just as fallible as our encoding and recoding, and just as liable to accidental falsehoods and embellishment as the rest of our memory process.
For something to be stored in our long-term memory is for it to transition from a fragile, fleeting object of focus to a solid, codified concept in our brain. This usually requires a deeper level of processing. We don’t tend to make strong connections from weakly-held information, and many facts and occurrences are only truly memorable because of the context at the time of noticing and encoding the information. This can stir up a fair bit of cognitive dissonance for us as designers. We know that deeper levels of processing require more conscious effort and more cognitive resources, but if we want something to be learnable, we almost have to strive for slower, more methodical interactions.
Retrieval
Information that is stored away in our long-term memory isn’t just immediately and miraculously retrievable. How much of the things you’ve felt, experienced, and learned recently do you think you’ll remember in ten years’ time? Or how much from ten years ago can you remember now? For most people, stored information does not necessarily stay as retrievable information.
Retrieval is a broad term for how we access previously-stored information. Through a process known as ecphory, we’re theorized to be able to reawaken memory traces, helping us recognise, recall, or relearn information we previously cataloged. Essentially, we’re bringing stored information back into our conscious awareness.
Retrieval often happens in response to a cue—an external or internal trigger of sorts—that allow us to access certain memories or stored information. We call this kind of retrieval recognition. We notice some aspect of our environment, or we feel a certain emotion or other type of interoception, and it triggers a memory of some kind. This is often related to the context or environment where encoding and storage occurred, like how going to your garden on a sunny day might trigger a reminder of a conversation you had at a family barbecue.
Retrieval and recognition are key when it comes to signifiers in our interfaces. Provided that the signifier was observed at the point of encoding, it’s quite probable that future encounters with this signifier will act as retrieval cues. Think about our video game example from Chapter 2, where yellow was used to indicate climbable surfaces. While the first encounter with this concept was novel, provided that encoding and storage worked at least somewhat well, the next encounter with that signifier then becomes a cue for recognition: ”the last time I saw this yellow, it meant that I could climb the surface.”
As we’ve seen, this process of encoding, storage, and retrieval is far from perfect. It has to happen countless times for a single stimulus to work its way through our attentional system, into our short-term or working memory, and finally to our long-term memory. All of that is only half the equation, too, as a memory lays dormant until we need to recall it, with this recall requiring a similar chain reaction of lighting neurons and synaptic activity. This results in some fascinating phenomena where memories that are stored are almost always slightly removed from the “pure” sensory input at the beginning of this chain reaction. We rarely remember anything in verism, seemingly relying on an acceptably low level of corruption to inform the truthfulness of what we recall. As you can probably guess, this opens up a scientific and philosophical minefield with implications ranging as far and wide as the objective trustworthiness of witnesses to crimes, the effectiveness of traditional educational exam structures, and the legitimacy of psychedelic experiences.
Designing for Intuition and Predictability
We’ve seen a lot of challenging and competing concepts already in this chapter. Firstly, we know that practice and repetition allow for automaticity, which in turn allows us to perform tasks and skills that were previously arduous and taxing without even consciously thinking about it. We also know that learning requires deeper levels of processing and more meaningful interactions. However, this all seemingly flies in the face of wanting to create simple, low-impact interfaces. How do we take these concepts and use them effectively and responsibly? The answer, rather paradoxically, is to start from a position of not really needing learnability.
Meeting expectations
In the previous chapter we looked at conventions and signifiers in some detail. Conventions are integral to providing a usable experience that doesn’t require learning. While we still have to consider things like working memory capacity and limiting options, and we would quite likely benefit in some way from a person remembering their experience with our work, we don’t have to worry about presenting novel concepts. Conventions by their very nature require little learning, they’re accepted norms, after all, and it’s quite likely that people who find their way to your product also use other products, where these conventions also exist.
We also know that signifiers help us to convey potentially complex possibilities through much simpler abstractions. While the first few encounters with a signifier will require some kind of encoding, re-coding, and storage of the represented concept, future encounters with the signifier will require much less cognitive overhead, provided that they’re consistent and predictable. And it’s this predictability that we’re most interested in when it comes to creating interfaces that can be intuited rather than learned. Whether it’s through convention, past experience, or exposure to your signifiers and system concepts, people will build expectations about what is possible in an environment and what certain qualities of certain elements might signify. It’s here that we encounter one of the most important concepts you’ll see when it comes to design cognition: the humble mental model.
Mental models
A mental model is the culmination of all of the assumptions and intuitions an individual holds about a system, including how its constituent parts perform and combine to make up a whole. Mental models are often simplified, zoomed-out assumptions (Norman, 1988) and rely heavily on heuristics and often metaphor. We tend to form mental models of many of the core aspects of our lives, including social dynamics, sociological and political ideologies, economics, and scientific and mathematical utilities. Our mental models have a huge say in how we perceive the world, yet they are flexible and malleable in nature, constantly shifting as we better grasp the world around us. We can also quite easily use our mental models to our own detriment.
Far too often we limit our perception of situations in our life based on a number of our existing mental models. Our worldview biases our perspective and can often lead to myopic reasoning, stubbornness, and dissonance. In the same vein, our unique combination of mental models can result in some quite innovative and refreshing ideas. Approaching a visual design problem with the mental models of cognitive psychology, for example, can lead to some rather creative, human-centered work. Similarly, approaching the same problem with the mental models of an economist might lead to a very different, equally interesting result.
Most importantly, mental models inform what people believe to be possible within a system or environment. Part of someone’s mental model of a shopping site might be if I click the Add to Cart button, this item will go in my shopping cart or if I click the Publish button, my work will be live straight away. It might also be something much more vague, like I could use this to edit my next video project or I can invite my whole team to this and collaborate in real-time. This might never be expressly or explicitly communicated to someone, but it’s inferred and expected by their previous interactions and perception of the interface or environment they’re exposed to. As we adhere to these expectations, we’re able to present intuitive, seamless environments. Imagine how you’d feel in an environment where every expectation you had was in some way incorrect—say, a hard wooden floor was suddenly bouncy and squishy, or a glass full of ice and water was somehow hot to the touch. Think how disorienting and confusing this would be to navigate. Suddenly hot things are cold and cold things are hot; every interaction is a surprise, and you cannot trust your intuition or predictive cognition. This would be a disaster to have to navigate, and you’d use a huge amount of cognitive energy to process the levels of dissonance to which you’ve been exposed.
This is the kind of environment we create when we defy convention too often. When everything is a novel experience, nothing can be predicted, and we create an environment full of dissonance, with possibilities and interactions that must be learned and memorized to be effective. The backbone of seamless design is the idea that intuition outdoes memorization. This idea forms the very basis of usability, and we rely on it every time we turn on a device and attempt to navigate designed environments. Thus, when we explore the need for learnability, we should assume that we’ve already ruled out the potentiality of making something intuitive. That is to say that either (a) the concept we’re conveying has no universal signifier or intuitive mental model around it—think early touch device, or newer, purely gestural interfaces)—or (b) that the unintuitive mental model we’re proposing represents an advantage that makes it worth learning. As we explored in Chapter 2, the acceptance among a population of a particular pattern or signifier portrays an extremely valid argument for convention; however, countless innovations, including the touch interfaces that revolutionized modern technology, would have never occurred if we always relied on or settled upon such conventions.
Common Mental Models
Many of the most universal interface concepts exist to provide an intuitive experience by making use of heuristics and real-world metaphors. Ideas such as the file and folder structure seen in most operating systems—or even the copy/cut/paste edit actions we see as universal when dealing with data such as text or images—are stellar examples of taking somewhat universal concepts from the real world, and abstracting away the complexities of a system to present a more intuitive, predictable model. Let’s take a look at some of the key concepts we’ll encounter in digital products, and how they’ve been abstracted in ways that encourage the forming of predictable mental models.
The Storage and Retrieval of Files or Data
A classic example of a conceptual model creating a predictable mental model is that of a computer’s folder and file structure (Figure 3-1). While our data isn’t actually stored on tiny sheets of paper and placed in tiny physical folders inside our computers—as fun as that imagery might be—we recognize the metaphor, and can build up a mental model to help us intuit behavior and possibilities within this conceptual model. The mental model here usually includes things like “this data (documents, web site, etc.) lives in this container (folder, tab, etc.).” For the most part, an underlying model of the deeper system is not required, and we defer to the simpler, more recognisable conceptual model.
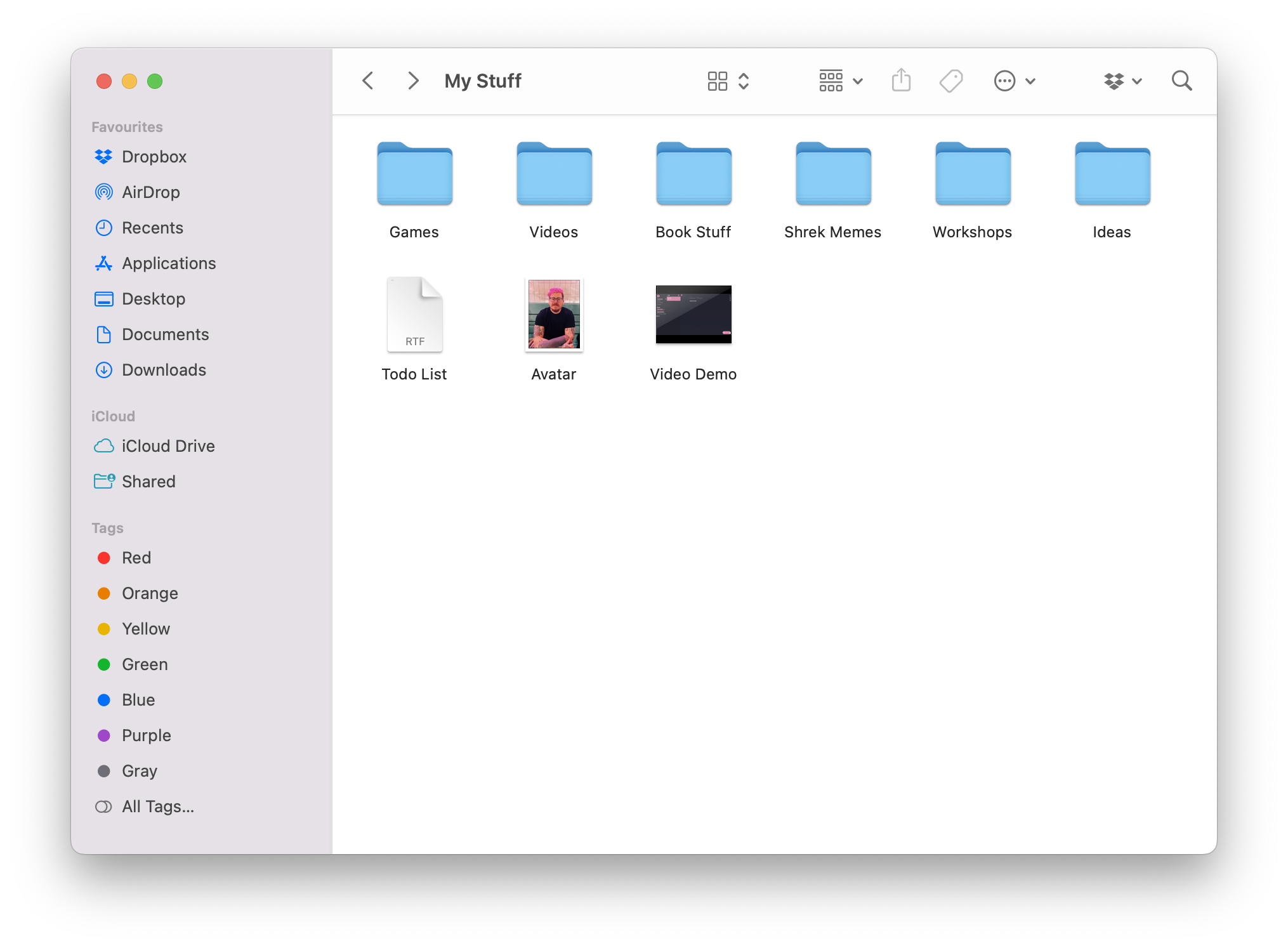 Figure 3-1. MacOS's file and folder structures
Figure 3-1. MacOS's file and folder structures
While a computer doesn’t have a bunch of physical folders that store physical documents, the design of the interface abstracts the system’s storage into an understandable model of the real world. Even if someone was to believe that computers performed this physical storage on our behalf, it really doesn’t matter that they’re wrong. Their model of the system is effective enough for them to never have to question its deeper workings. For someone who has to deal with the inner workings of a system—say, a computer technician or an operating system engineer—their model will be clearly different. In this case, they’d likely have to have a deeper understanding of the machinations of the system—that is, the fact that computers use digital storage, encoding, and decoding for data storage and retrieval—as opposed to the shallower understanding provided by the file/folder metaphor.
Similarly, when it comes to storing and retrieving data within, for example, a web or mobile application, the metaphors used to communicate an adequate model of the system don’t necessarily need to inform people of the underlying server or database structure. In fact, one of the biggest mistakes we can make (as we touched on in Chapter 1) is assuming that people external to our organization will have a similar understanding of our category structure as us and our teammates. This also applies when communicating the models of our systems. If we assume that the underlying data structure, such as the schema of our database, is the best way to structure data externally, then we run the risk of communicating a too-technical, overly literal model. Where data is stored and how it’s sent there is usually of no concern to someone who just wants to manipulate or store it. An extremely common oversight is to not abstract your system’s structure into a clearer conceptual model. Sometimes this can be as simple as renaming a verbose error message to a more straightforward oops! that message failed to send, try again!—other times it can be obfuscating huge chunks of your system model behind simple and effective metaphors, just like the file and folder model we’re so adept at navigating.
Sending and Receiving Communication
One of the most successful conceptual models is that of the humble email inbox. Similar to the file and folder structure explored above, email inboxes mimic a real-world concept—although I can’t say I’ve ever actually interacted with a real-life inbox—and adheres to a set of qualities observed in the real-world object to ensure familiarity and predictability. A real inbox on your desk contains letters, notes, and other forms of information that might be relevant to you.
In the olden days, when you’d sit down at your desk to work—if you were a very important business person at least—you’d find your inbox full of things that might need your attention. You might then quickly glance through everything in there, file away items of importance; discard stuff that doesn’t matter, or doesn’t need to stick around; and even label or mark-up certain items that might require further action. You can do all of this in many digital inboxes too. Take Gmail (Figure 3-2) for example: you have a list of messages, sorted by most recently received (just like your latest message in a physical inbox would be placed at the top), alongside the ability to do things like archive, delete, annotate, and reply.
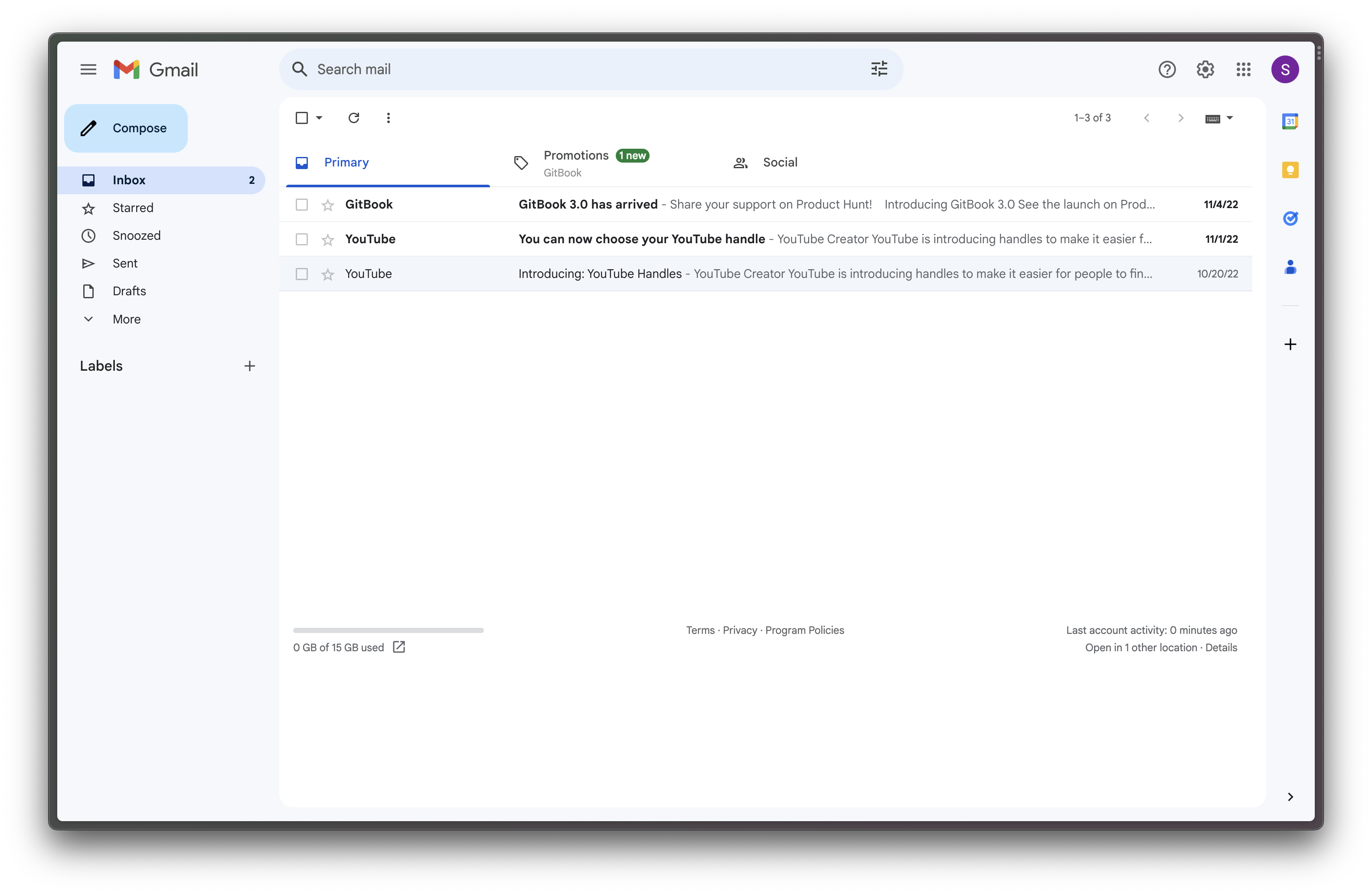 Figure 3-2: Gmail's inbox broadly behaves like an old physical inbox you'd find on someone's desk.
Figure 3-2: Gmail's inbox broadly behaves like an old physical inbox you'd find on someone's desk.
This inbox model became so universally adopted that it’s essentially the default structure for all types of messaging applications. However, as the world moves towards more real-time communication, and more and more of our interactions take place in the digital sphere, messaging applications have brought in other conceptual models to embrace this more ephemeral, transient means of digital communication.
A great example of this is emoji reactions. Seen commonly in workplace apps like Slack, and making their way through almost every personal messaging application in recent years, emoji reactions provide a conceptual model that’s somewhat akin to body language. This might sound like a strange claim, but think about it: when we have real-world, face-to-face conversations with people, we almost always communicate feelings—agreement, disagreement, disgust, adulation—through our physical reactions just as much as our verbal ones. If we see a message thread as more akin to a conversation than the stuffy confines of a business inbox back-and-forth, then we are almost completely missing this kind of conversational metadata that we provide through body language. Emoji reactions (Figure 3-3) give us a lightweight and more immediate means of expressing wordless response. While not specifically a mental model of any kind of real-world object, it brings a facsimile of an extremely important real-world concept into the digital realm.
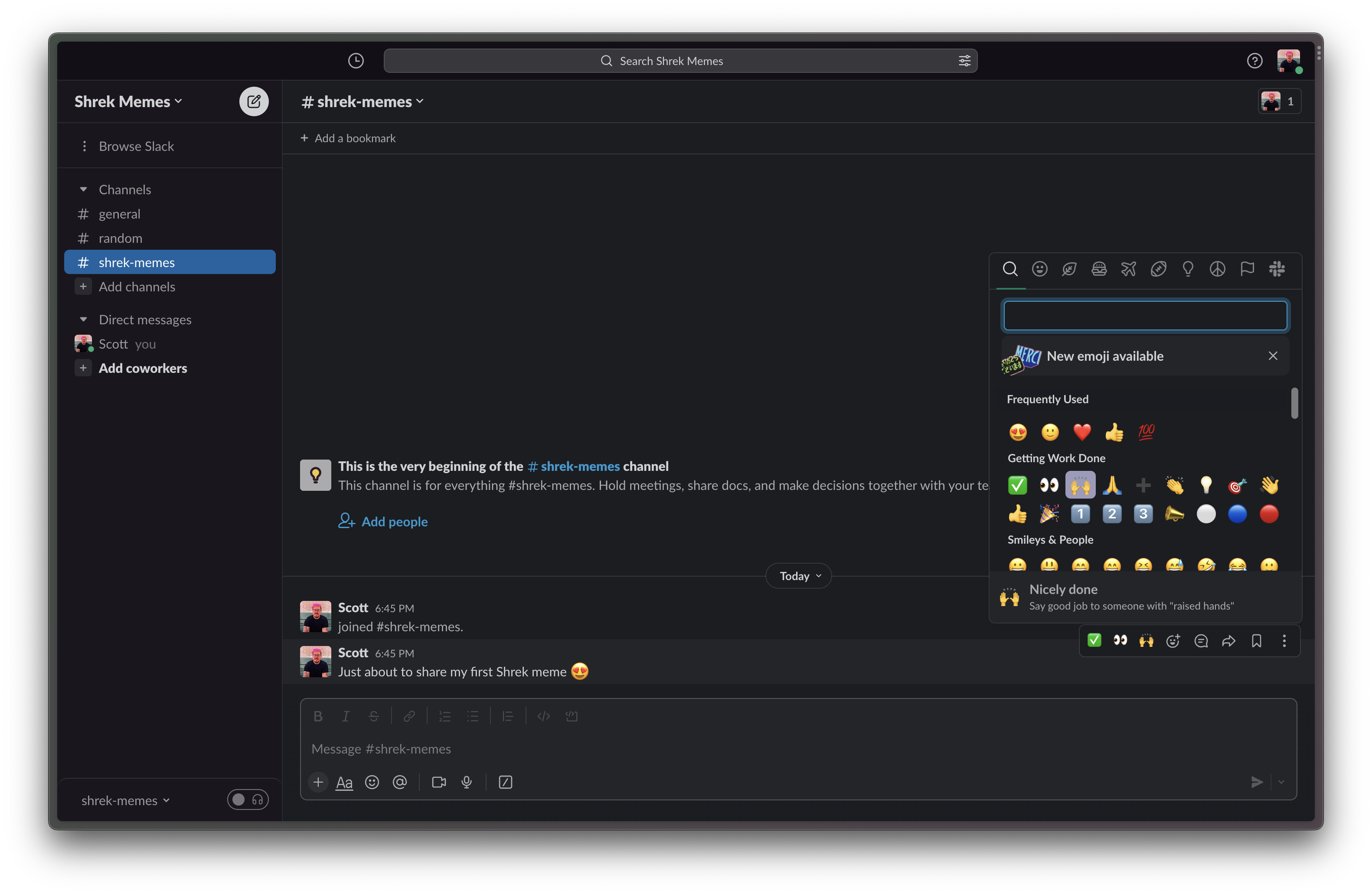 Figure 3-3: Emoji reactions in Slack
Figure 3-3: Emoji reactions in Slack
The Creation and Manipulation of Media
Design products, like Figma in Figure 3-4, portray a “canvas”-centric interface containing features such as a pen tool, pencil tool, and various shape-drawing options.
This makes Figma, and design tools like it, conducive to a mental model of the tools we use to create and draw in the real world.
Adobe’s Lightroom (Figure 3-5) uses language and concepts related to the analogue world of developing film photography, again allowing for the application of a real-world mental model.
Like this preview? Buy the book.
This is a sample, a smidgen of the full chapter. If you like what you’ve read, grab the book to continue learning!
Buy the Book